之前的3篇博客主要讲了如何处理单个工作表。但是,很多情况下我们需要处理多个工作表,如果手工处理的话,效率会非常低,甚至根本不可行。在这种情况下,Python可以让我们自动化和规模化地进行数据处理,远远超过手工处理能够达到的限度。
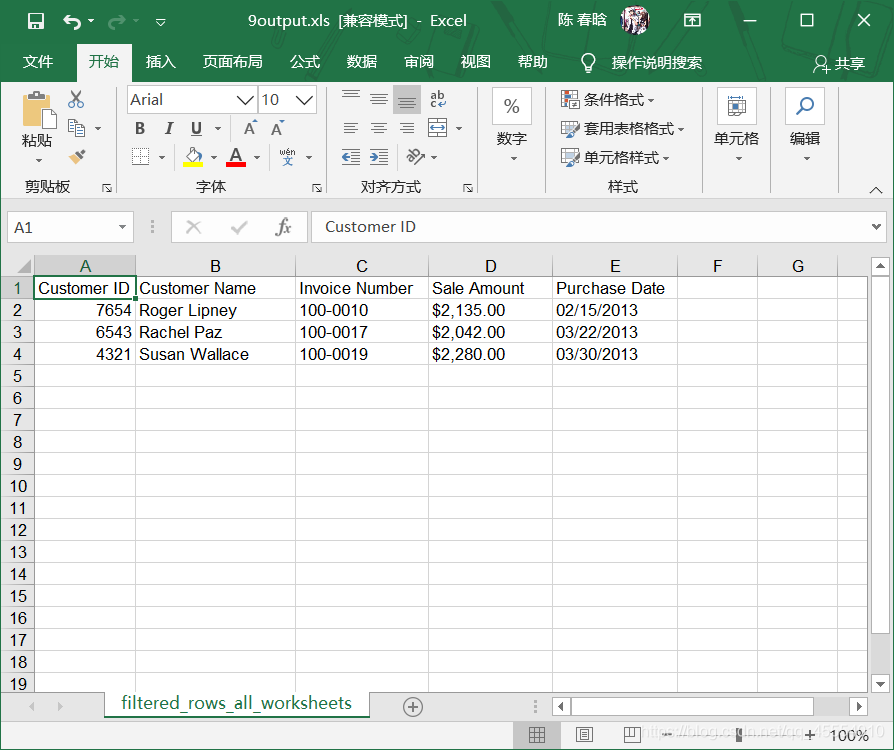
在所有工作表中筛选特定行 1.基础Python 对于《Python数据分析基础之Excel文件(1)》 中建立的sales_2013.xlsx这个Excel工作簿,我们想在所有工作表中筛选出销售额大于$2,000.00的所有行。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #!/usr/bin/env python3 import sys from datetime import date from xlrd import open_workbook, xldate_as_tuple from xlwt import Workbook input_file = sys.argv[1] output_file = sys.argv[2] output_workbook = Workbook() output_worksheet = output_workbook.add_sheet('filtered_rows_all_worksheets') sales_column_index = 3 threshold = 2000.0 first_worksheet = True with open_workbook(input_file) as workbook: data = [] for worksheet in workbook.sheets(): if first_worksheet: header_row = worksheet.row_values(0) data.append(header_row) first_worksheet = False for row_index in range(1, worksheet.nrows): row_list = [] sale_amount = worksheet.cell_value(row_index, sales_column_index) sale_amount = sale_amount.replace(r'$', '') sale_amount = sale_amount.replace(r',', '') sale_amount = float(sale_amount) if sale_amount > threshold: for column_index in range(worksheet.ncols): cell_value = worksheet.cell_value(row_index, column_index) cell_type = worksheet.cell_type(row_index, column_index) if cell_type == 3: date_cell = xldate_as_tuple(cell_value, workbook.datemode) date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y') row_list.append(date_cell) else: row_list.append(cell_value) if row_list: data.append(row_list) for list_index, output_list in enumerate(data): for element_index, element in enumerate(output_list): output_worksheet.write(list_index, element_index, element) output_workbook.save(output_file)
在上面的代码中,变量sales_column_index保存Sale Amount列的索引值,变量threshold保存我们关心的销售额。我们要做的是将Sale Amount列中的每个值与这个阈值进行比较,以此来确定哪一行要被写入输出文件中。变量first_worksheet则是一个旗帜,其作用是用来判断当前工作表是否为第一个工作表。初始化旗帜时,我们将其设为True。data中,然后令first_worksheet = False,继续处理余下的行。
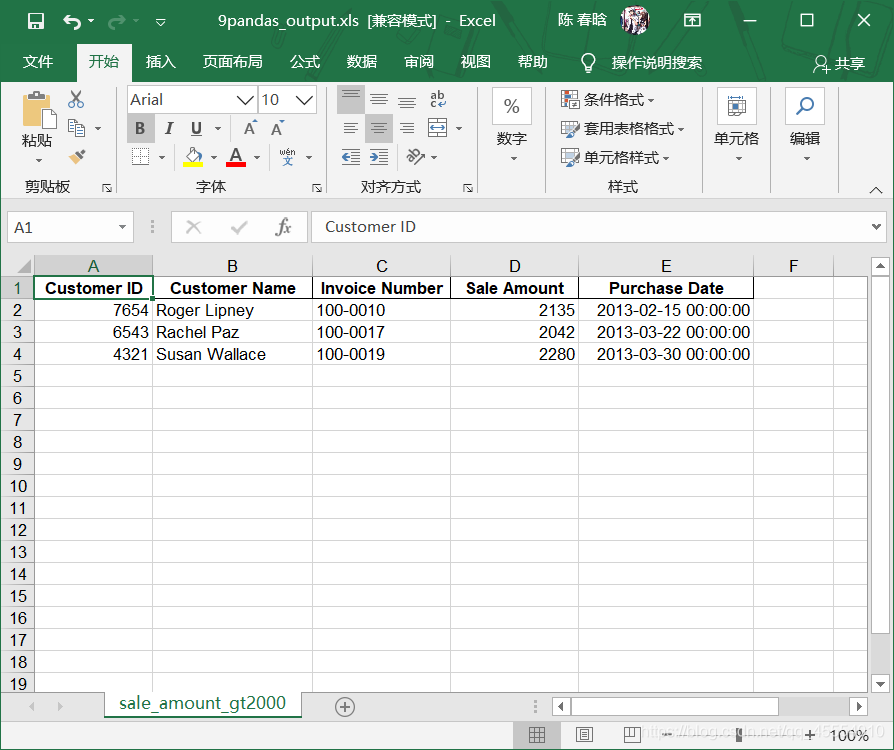
2.pandas 在pandas模块中,通过在read_excel()函数中设置sheet_name=None,可以一次性读取工作簿中的所有工作表。pandas将这些工作表读入一个数据框字典,字典中的键就是工作表的名称,值就是包含工作表中数据的数据框。通过在字典的键和值之间迭代,就可以使用工作簿中所有的数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #!/usr/bin/env python3 import pandas as pd import sys input_file = sys.argv[1] output_file = sys.argv[2] data_frame = pd.read_excel(input_file, sheet_name=None, index_col=None) row_output = [] for worksheet_name, data in data_frame.items(): data['Sale Amount'] = data['Sale Amount'].str.replace(r'\$', '') data['Sale Amount'] = data['Sale Amount'].str.replace(r',', '') data['Sale Amount'] = data['Sale Amount'].astype(float) row_output.append(data[data['Sale Amount'].astype(float) > 2000.0]) filtered_rows = pd.concat(row_output, axis=0, ignore_index=True) writer = pd.ExcelWriter(output_file) filtered_rows.to_excel(writer, sheet_name='sale_amount_gt2000', index=False) writer.save()
在命令行窗口中运行这个脚本,并打开输出文件查看结果。
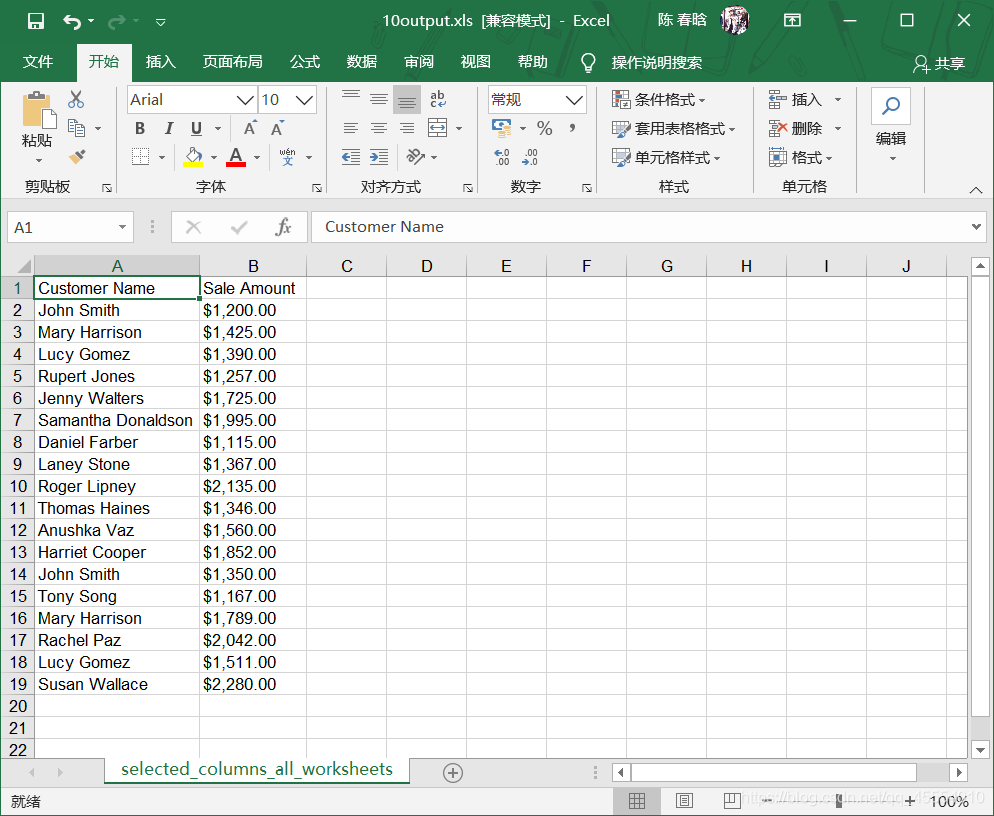
在所有工作表中选取特定列 1.基础Python 对于《Python数据分析基础之Excel文件(1)》 中建立的sales_2013.xlsx这个Excel工作簿,我们想在所有工作表中选取Customer Name和Sale Amount列。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #!/usr/bin/env python3 import sys from datetime import date from xlrd import open_workbook, xldate_as_tuple from xlwt import Workbook input_file = sys.argv[1] output_file = sys.argv[2] output_workbook = Workbook() output_worksheet = output_workbook.add_sheet('selected_columns_all_worksheets') my_columns = ['Customer Name', 'Sale Amount'] first_worksheet = True with open_workbook(input_file) as workbook: data = [my_columns] index_of_cols_to_keep = [] for worksheet in workbook.sheets(): if first_worksheet: header = worksheet.row_values(0) for column_index in range(len(header)): if header[column_index] in my_columns: index_of_cols_to_keep.append(column_index) first_worksheet = False for row_index in range(1, worksheet.nrows): row_list = [] for column_index in index_of_cols_to_keep: cell_value = worksheet.cell_value(row_index, column_index) cell_type = worksheet.cell_type(row_index, column_index) if cell_type == 3: date_cell = xldate_as_tuple(cell_value, workbook.datemode) date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y') row_list.append(date_cell) else: row_list.append(cell_value) data.append(row_list) for list_index, output_list in enumerate(data): for element_index, element in enumerate(output_list): output_worksheet.write(list_index, element_index, element) output_workbook.save(output_file)
列表变量my_columns包含了我们要保留的两列的名称。将my_columns放入data,作为data中的第一个列表,因为它是要写入输出文件的列的标题。列表变量index_of_cols_to_keep用来保存Customer Name和Sale Amount列的索引值。
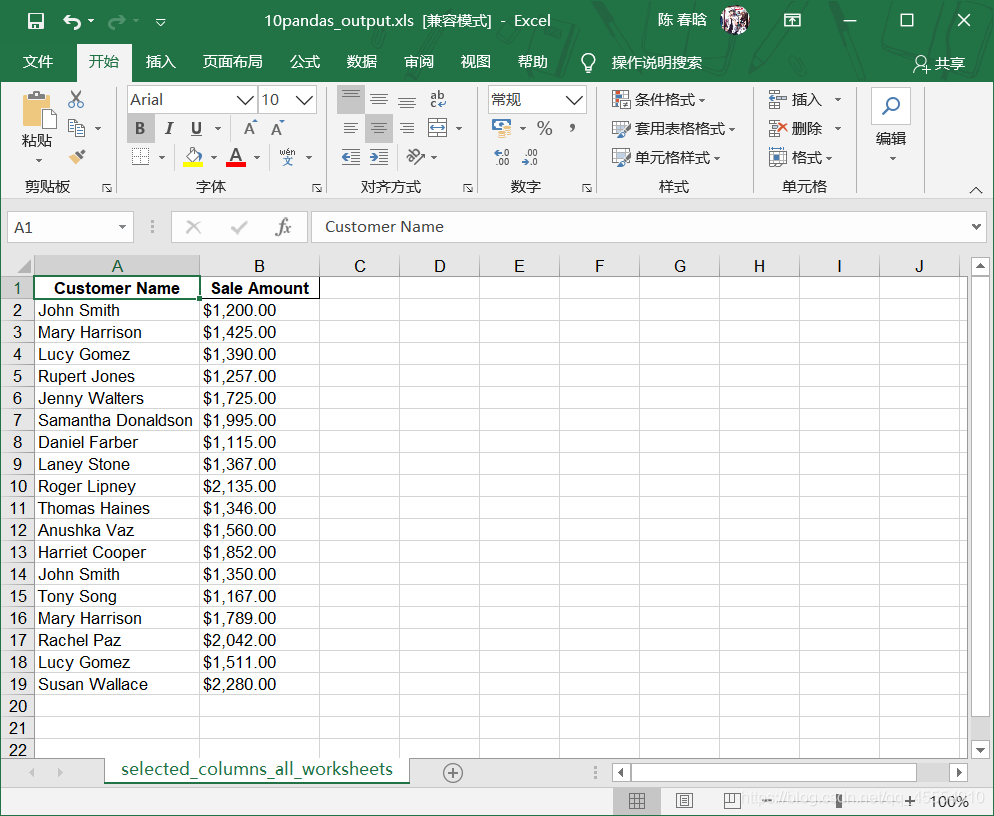
2.pandas 使用pandas模块的思路和上面筛选特定列的思路类似,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #!/usr/bin/env python3 import pandas as pd import sys input_file = sys.argv[1] output_file = sys.argv[2] data_frame = pd.read_excel(input_file, sheet_name=None, index_col=None) column_output = [] for worksheet_name, data in data_frame.items(): column_output.append(data.loc[:, ['Customer Name', 'Sale Amount']]) selected_columns = pd.concat(column_output, axis=0, ignore_index=True) writer = pd.ExcelWriter(output_file) selected_columns.to_excel(writer, sheet_name='selected_columns_all_worksheets', index=False) writer.save()
在命令行窗口中运行这个脚本,并打开输出文件查看结果。