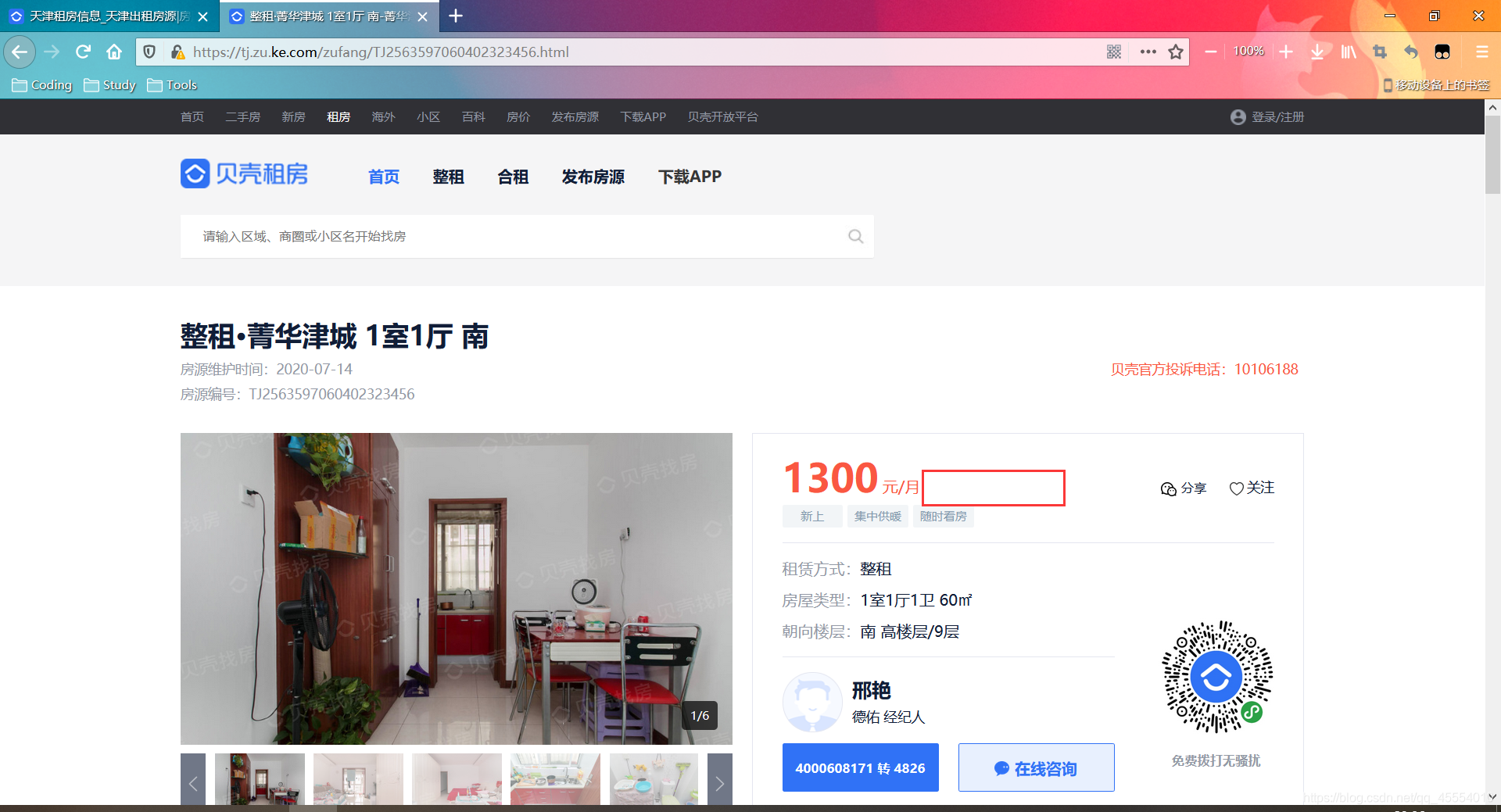
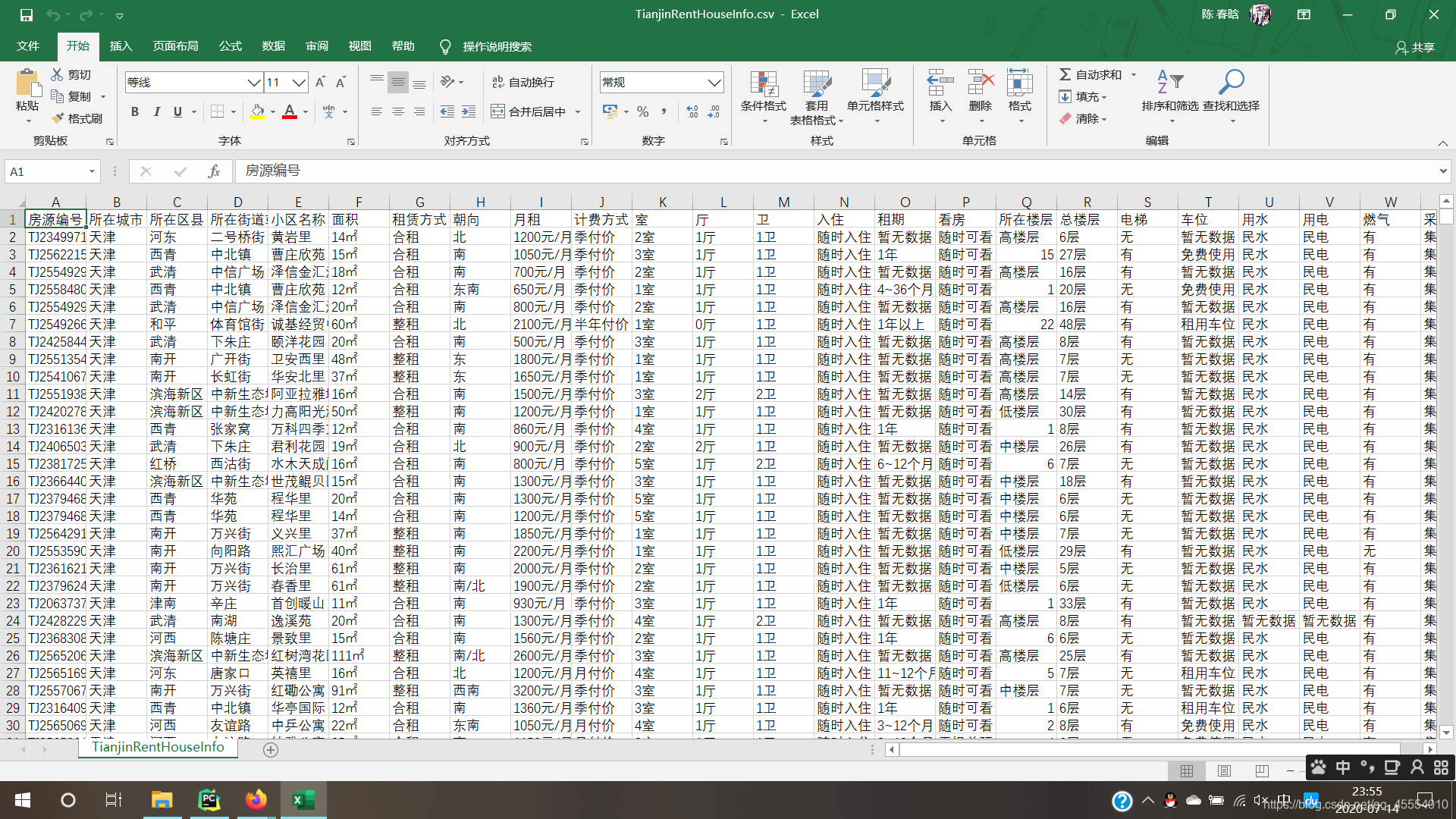
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| #!/usr/bin/env python3
# -*- coding: utf-8 -*-
import csv
import re
from bs4 import BeautifulSoup
import requests
head = ['房源编号', '所在城市', '所在区县', '所在街道或地区', '小区名称', '面积', '租赁方式', '朝向', '月租', '计费方式', '室', '厅',
'卫', '入住', '租期', '看房', '所在楼层', '总楼层', '电梯', '车位', '用水', '用电', '燃气', '采暖'] # 写入文件的标题行
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0'}
with open('TianjinRentHouseInfo.csv', 'w', newline='') as csv_out_file:
filewriter = csv.writer(csv_out_file)
filewriter.writerow(head)
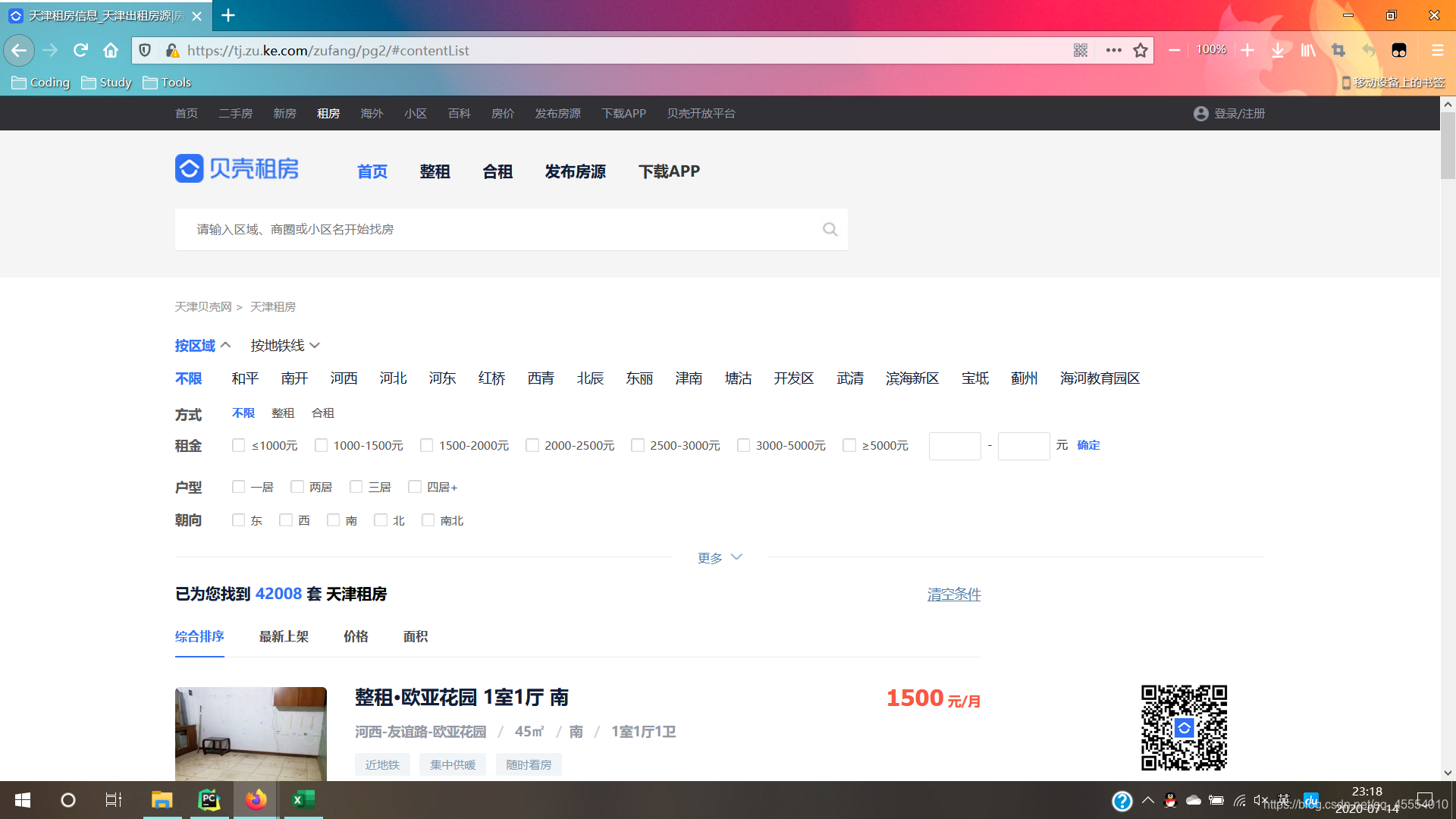
for page in range(1, 51):
url = 'https://tj.zu.ke.com/zufang/pg' + str(page) + '/#contentList'
response = requests.get(url=url, headers=headers)
page_text = response.text
soup = BeautifulSoup(page_text, 'html.parser')
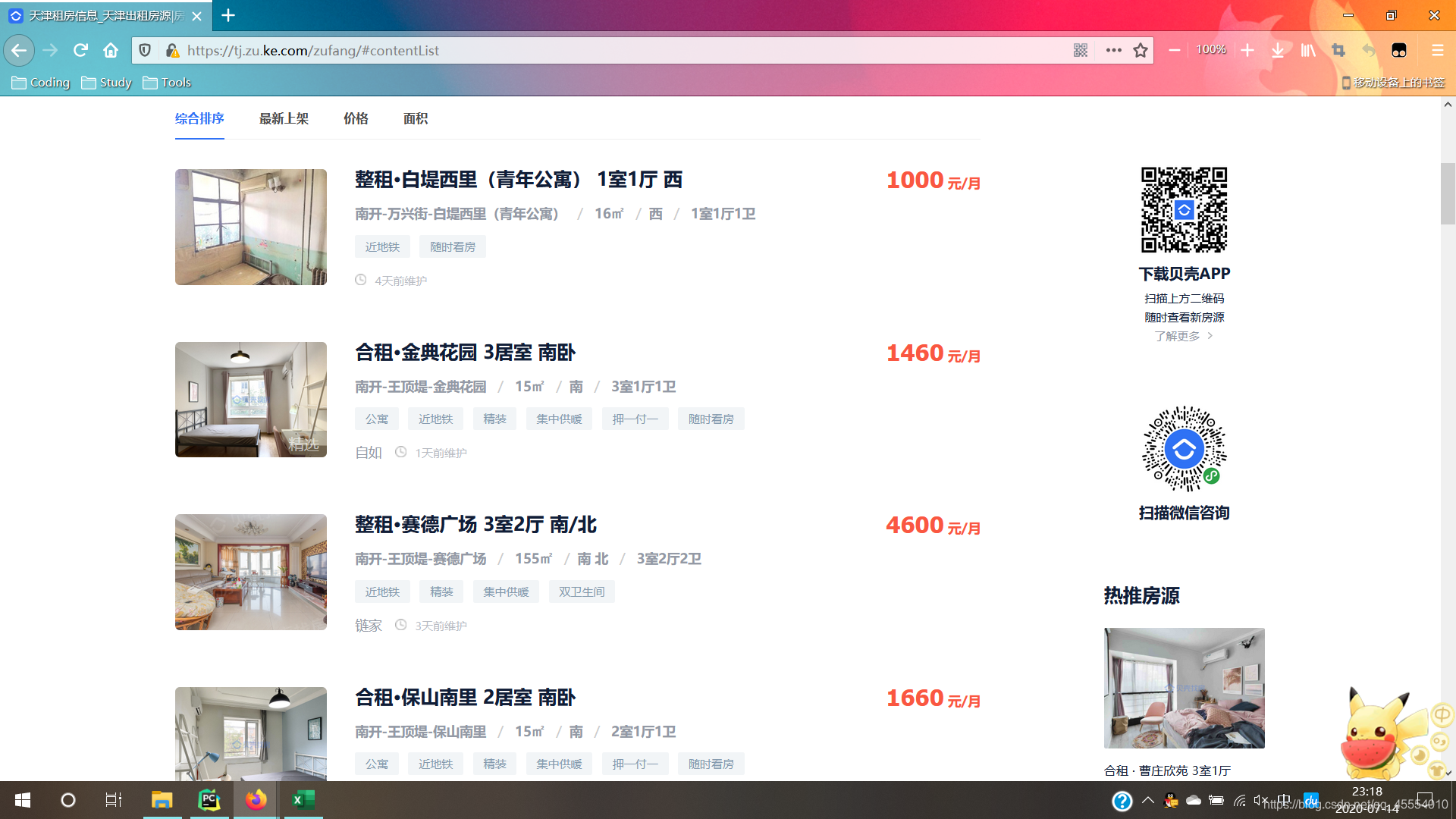
div_list = soup.find_all(class_='content__list--item')
codes = [] # 存储房源编号的列表
areas = [] # 存储房源地区的列表
for div in div_list:
code = re.search(r'data-house_code="(.*?)" ', str(div)).group()[17:-2]
codes.append(code)
p_list = soup.find_all(class_='content__list--item--des')
for p in p_list:
a_list = p.find_all('a')
area = []
for i in range(len(a_list)):
a_text = a_list[i].text
area.append(a_text)
areas.append(area)
for i in range(len(codes)):
info = [] # 存储房源信息的列表
info.extend([codes[i], '天津'] + areas[i])
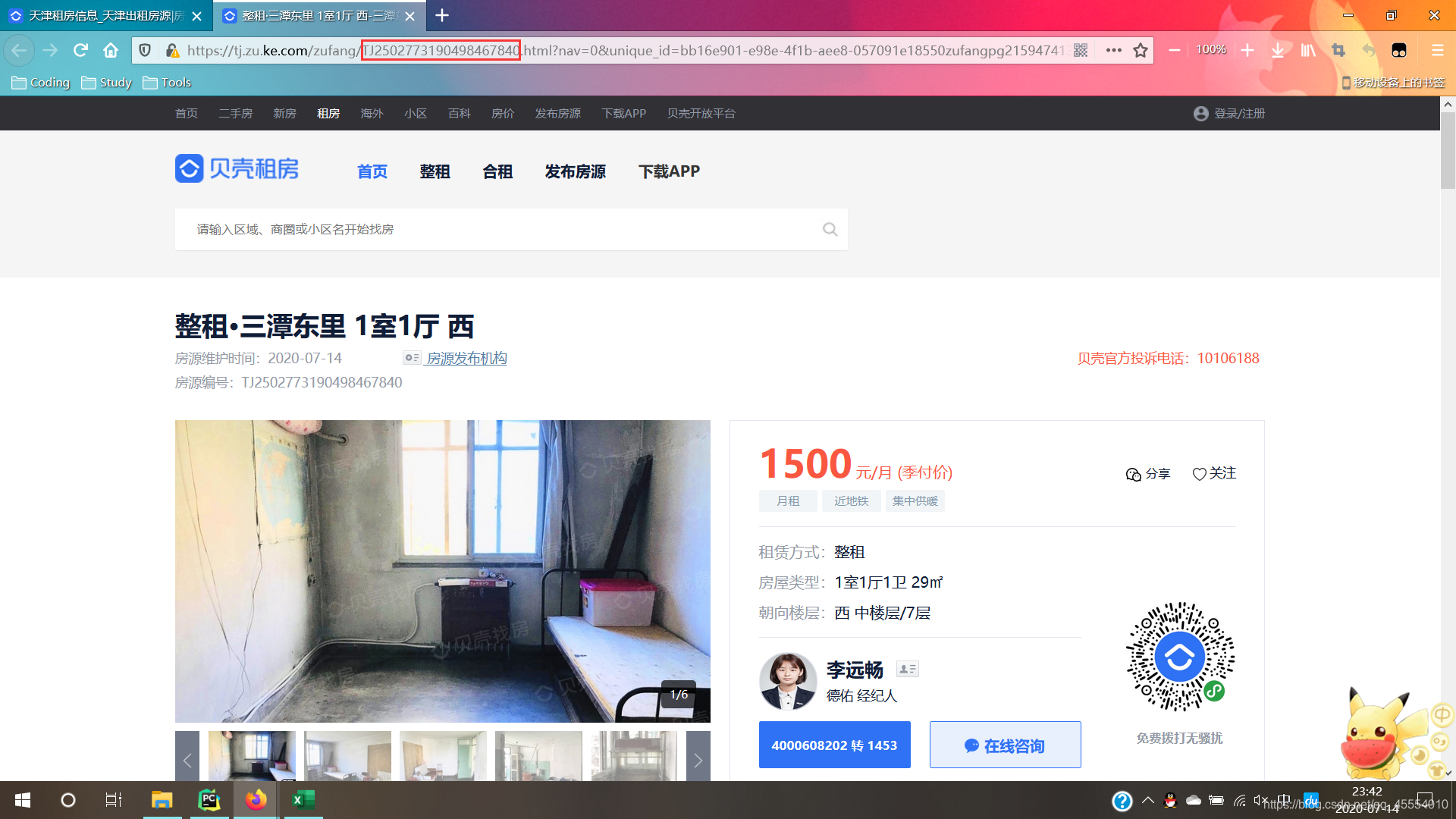
url = 'https://tj.zu.ke.com/zufang/' + codes[i] + '.html'
response = requests.get(url=url, headers=headers)
page_text = response.text
soup = BeautifulSoup(page_text, 'html.parser')
ul_text = soup.find('ul', class_='content__aside__list').text
div_text = soup.find('div', class_='content__aside--title').text
S = re.search(r' (.*?)㎡', ul_text).group()[1:] # 面积
lease = re.search(r'租赁方式:(.*?)\n', ul_text).group()[5:-1] # 租赁方式
aspect = re.search(r'朝向楼层:(.*?) ', ul_text).group()[5:-1] # 朝向
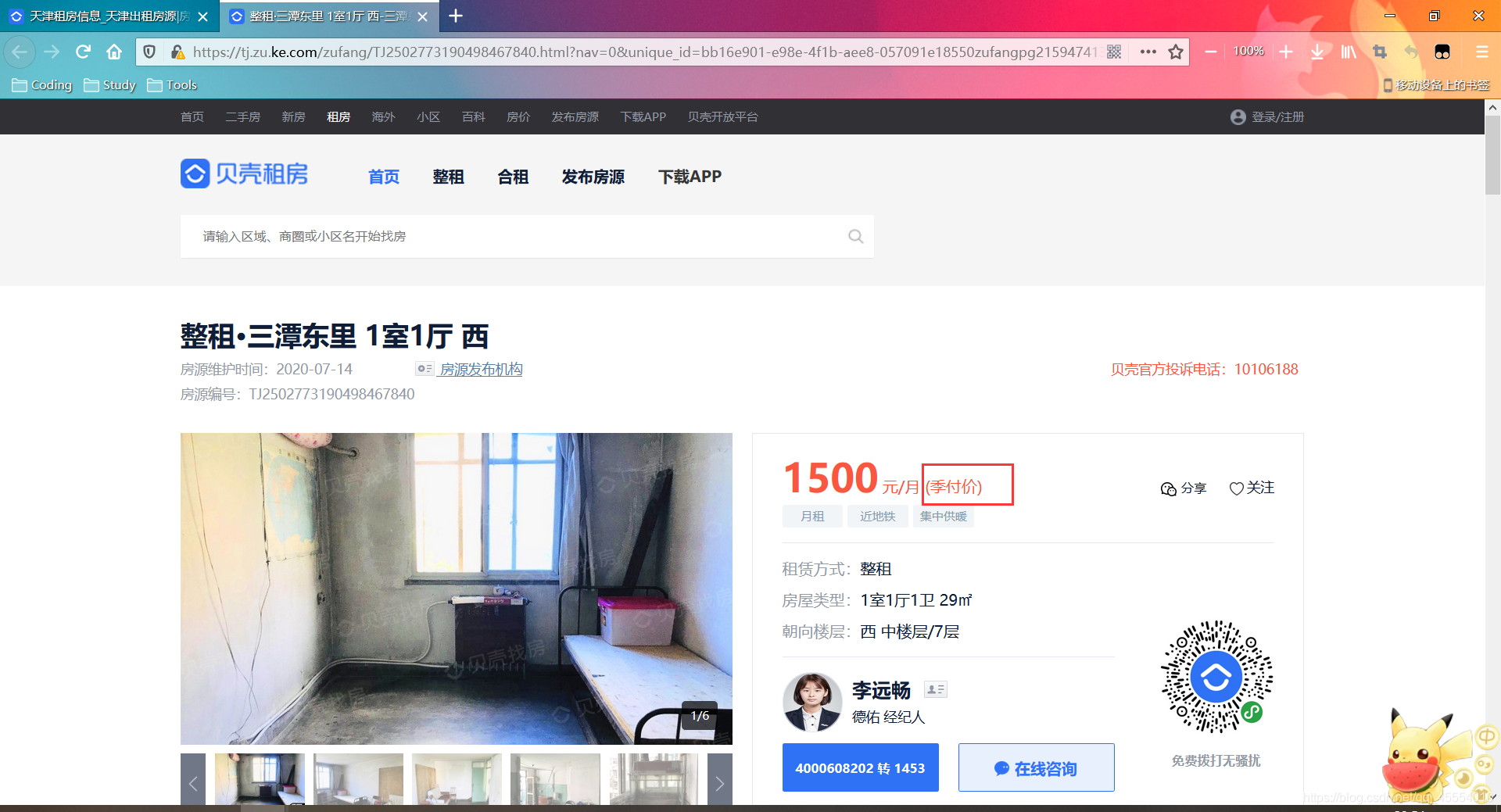
price = re.search(r'([0-9]*?)元/月', div_text).group() # 月租
try:
charge_mode = re.search(r'\((.*?)\)', div_text).group()[1:-1] # 计费方式
except AttributeError:
charge_mode = 'None'
room = re.search(r'([0-9*?])室', ul_text).group() # 几室
hall = re.search(r'([0-9*?])厅', ul_text).group() # 几厅
toilet = re.search(r'([0-9*?])卫', ul_text).group() # 几卫
info.extend([S, lease, aspect, price, charge_mode, room, hall, toilet])
div = soup.find('div', class_='content__article__info')
ul_list = div.find_all('ul')
ul_text = ''
for ul in ul_list:
ul_text += ul.text
check_in = re.search(r'入住:(.*?)\n', ul_text).group()[3:-1] # 入住
term = re.search(r'租期:(.*?)\n', ul_text).group()[3:-1] # 租期
see_house = re.search(r'看房:(.*?)\n', ul_text).group()[3:-1] # 看房
floor = re.search(r'楼层:(.*?)/', ul_text).group()[3:-1] # 所在楼层
total_floor = re.search(r'/(.*?)\n', ul_text).group()[1:-1] # 总楼层
lift = re.search(r'电梯:(.*?)\n', ul_text).group()[3:-1] # 电梯
stall = re.search(r'车位:(.*?)\n', ul_text).group()[3:-1] # 车位
water = re.search(r'用水:(.*?)\n', ul_text).group()[3:-1] # 用水
elec = re.search(r'用电:(.*?)\n', ul_text).group()[3:-1] # 用电
gas = re.search(r'燃气:(.*?)\n', ul_text).group()[3:-1] # 燃气
heating = re.search(r'采暖:(.*?)\n', ul_text).group()[3:-1] # 采暖
info.extend([check_in, term, see_house, floor, total_floor, lift, stall, water, elec, gas, heating])
print(info[0], '写入成功')
filewriter.writerow(info)
|