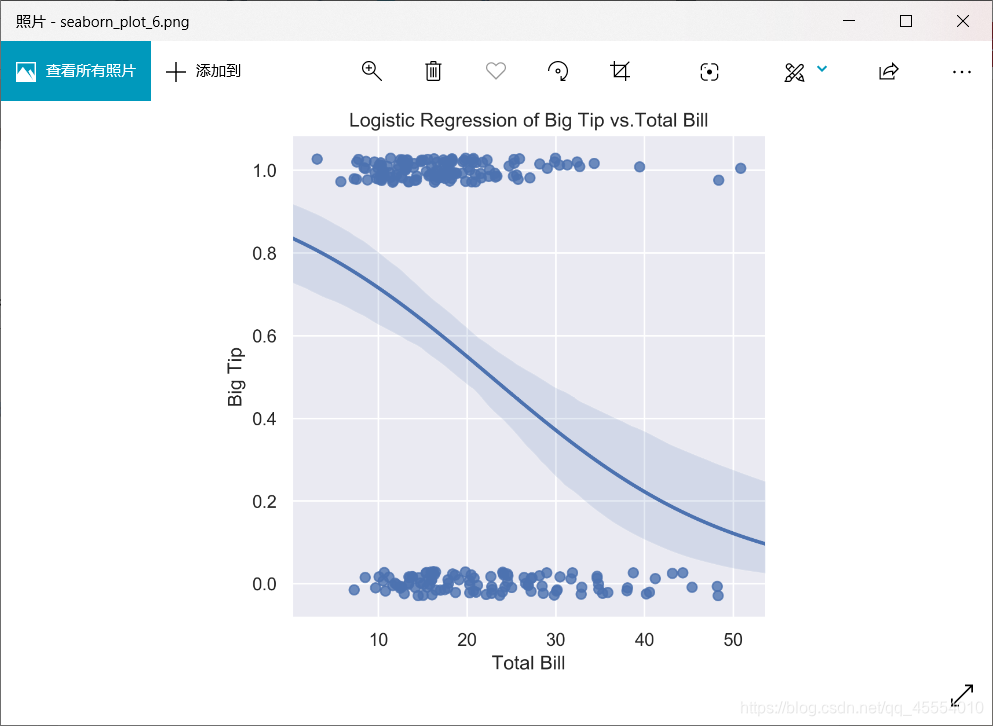
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| OLS Regression Results
==============================================================================
Dep. Variable: quality R-squared: 0.292
Model: OLS Adj. R-squared: 0.291
Method: Least Squares F-statistic: 243.3
Date: Thu, 27 Feb 2020 Prob (F-statistic): 0.00
Time: 23:03:10 Log-Likelihood: -7215.5
No. Observations: 6497 AIC: 1.445e+04
Df Residuals: 6485 BIC: 1.454e+04
Df Model: 11
Covariance Type: nonrobust
========================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------------
Intercept 55.7627 11.894 4.688 0.000 32.447 79.079
alcohol 0.2670 0.017 15.963 0.000 0.234 0.300
chlorides -0.4837 0.333 -1.454 0.146 -1.136 0.168
citric_acid -0.1097 0.080 -1.377 0.168 -0.266 0.046
density -54.9669 12.137 -4.529 0.000 -78.760 -31.173
fixed_acidity 0.0677 0.016 4.346 0.000 0.037 0.098
free_sulfur_dioxide 0.0060 0.001 7.948 0.000 0.004 0.007
pH 0.4393 0.090 4.861 0.000 0.262 0.616
residual_sugar 0.0436 0.005 8.449 0.000 0.033 0.054
sulphates 0.7683 0.076 10.092 0.000 0.619 0.917
total_sulfur_dioxide -0.0025 0.000 -8.969 0.000 -0.003 -0.002
volatile_acidity -1.3279 0.077 -17.162 0.000 -1.480 -1.176
==============================================================================
Omnibus: 144.075 Durbin-Watson: 1.646
Prob(Omnibus): 0.000 Jarque-Bera (JB): 324.712
Skew: -0.006 Prob(JB): 3.09e-71
Kurtosis: 4.095 Cond. No. 2.49e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 2.49e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
Quantities you can extract from the result:
['HC0_se', 'HC1_se', 'HC2_se', 'HC3_se', '_HCCM', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_cache', '_data_attr', '_get_robustcov_results', '_is_nested', '_wexog_singular_values', 'aic', 'bic', 'bse', 'centered_tss', 'compare_f_test', 'compare_lm_test', 'compare_lr_test', 'condition_number', 'conf_int', 'conf_int_el', 'cov_HC0', 'cov_HC1', 'cov_HC2', 'cov_HC3', 'cov_kwds', 'cov_params', 'cov_type', 'df_model', 'df_resid', 'diagn', 'eigenvals', 'el_test', 'ess', 'f_pvalue', 'f_test', 'fittedvalues', 'fvalue', 'get_influence', 'get_prediction', 'get_robustcov_results', 'initialize', 'k_constant', 'llf', 'load', 'model', 'mse_model', 'mse_resid', 'mse_total', 'nobs', 'normalized_cov_params', 'outlier_test', 'params', 'predict', 'pvalues', 'remove_data', 'resid', 'resid_pearson', 'rsquared', 'rsquared_adj', 'save', 'scale', 'ssr', 'summary', 'summary2', 't_test', 't_test_pairwise', 'tvalues', 'uncentered_tss', 'use_t', 'wald_test', 'wald_test_terms', 'wresid']
Coefficients:
Intercept 55.762750
alcohol 0.267030
chlorides -0.483714
citric_acid -0.109657
density -54.966942
fixed_acidity 0.067684
free_sulfur_dioxide 0.005970
pH 0.439296
residual_sugar 0.043559
sulphates 0.768252
total_sulfur_dioxide -0.002481
volatile_acidity -1.327892
dtype: float64
Coefficient Std Errors:
Intercept 11.893899
alcohol 0.016728
chlorides 0.332683
citric_acid 0.079619
density 12.137473
fixed_acidity 0.015573
free_sulfur_dioxide 0.000751
pH 0.090371
residual_sugar 0.005156
sulphates 0.076123
total_sulfur_dioxide 0.000277
volatile_acidity 0.077373
dtype: float64
Adj. R-squared:
0.29
F-statistic: 243.3 P-value: 0.00
Number of obs: 6497 Number of fitted values: 6497
|
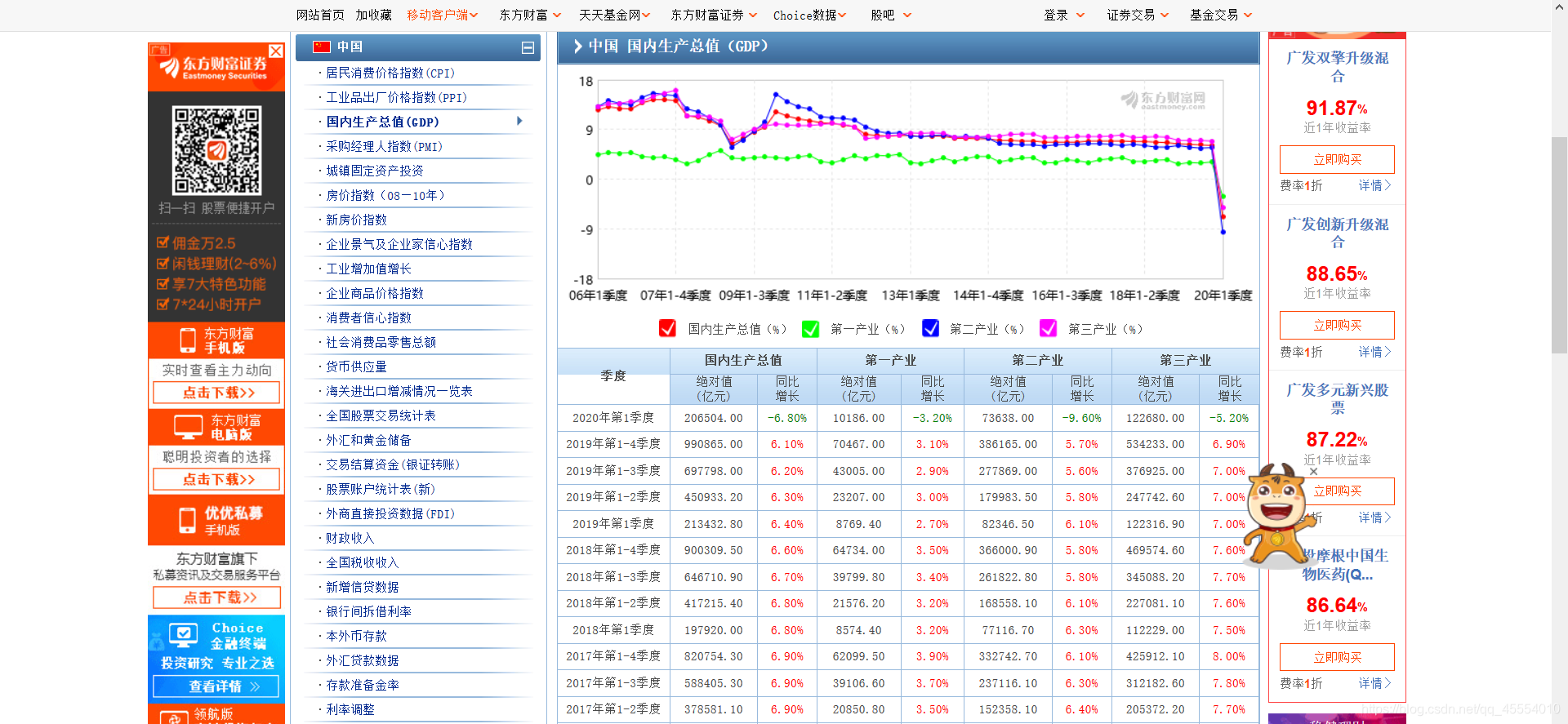
 )
)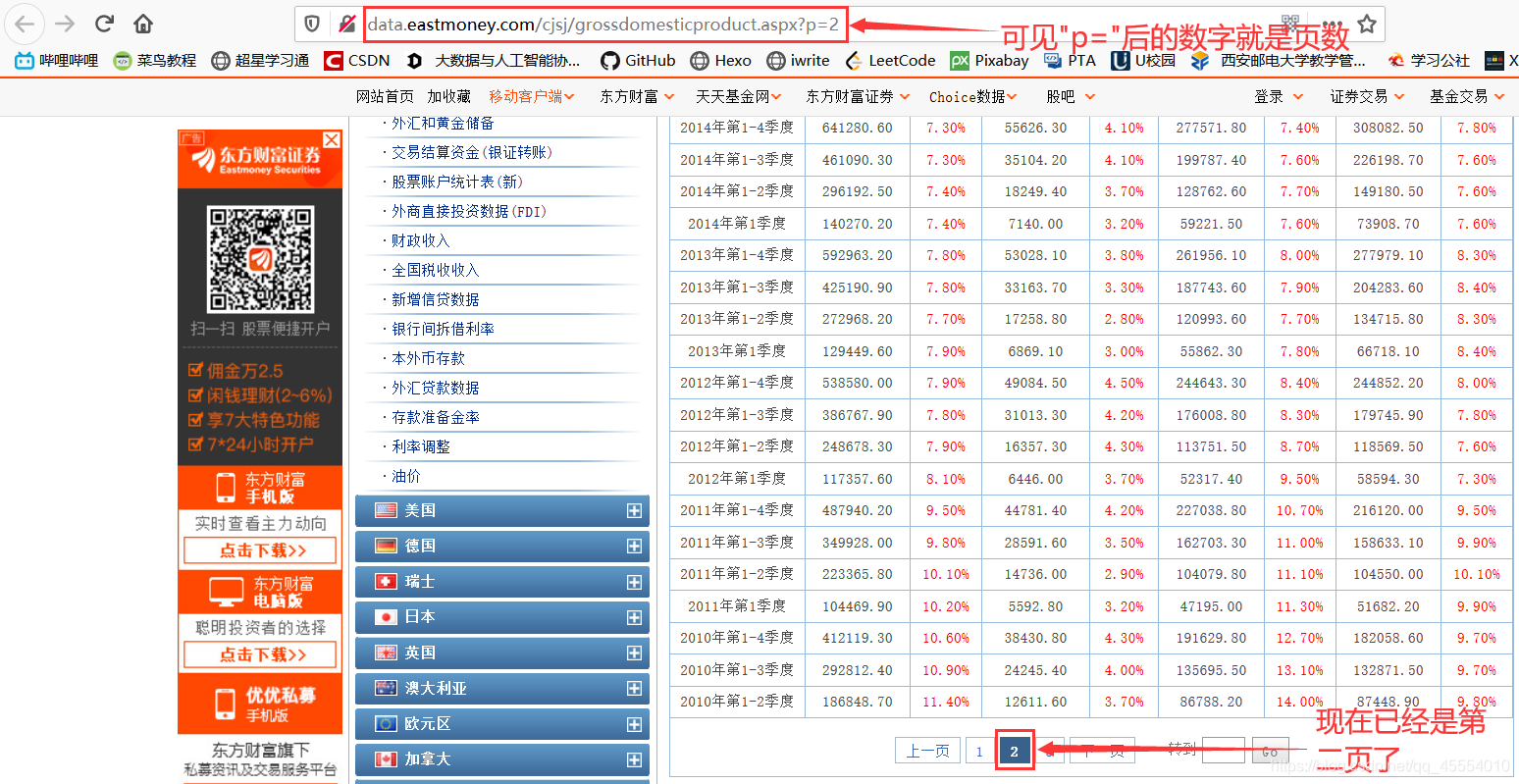
 )
)



 )
) )
)


 )
)

 )
) )
) )
) )
) )
)

 )
)






 )
) 在操作菜单中点击创建基本任务,并在创建基本任务向导中填写名称和描述,然后点击下一步。
在操作菜单中点击创建基本任务,并在创建基本任务向导中填写名称和描述,然后点击下一步。








 )
)





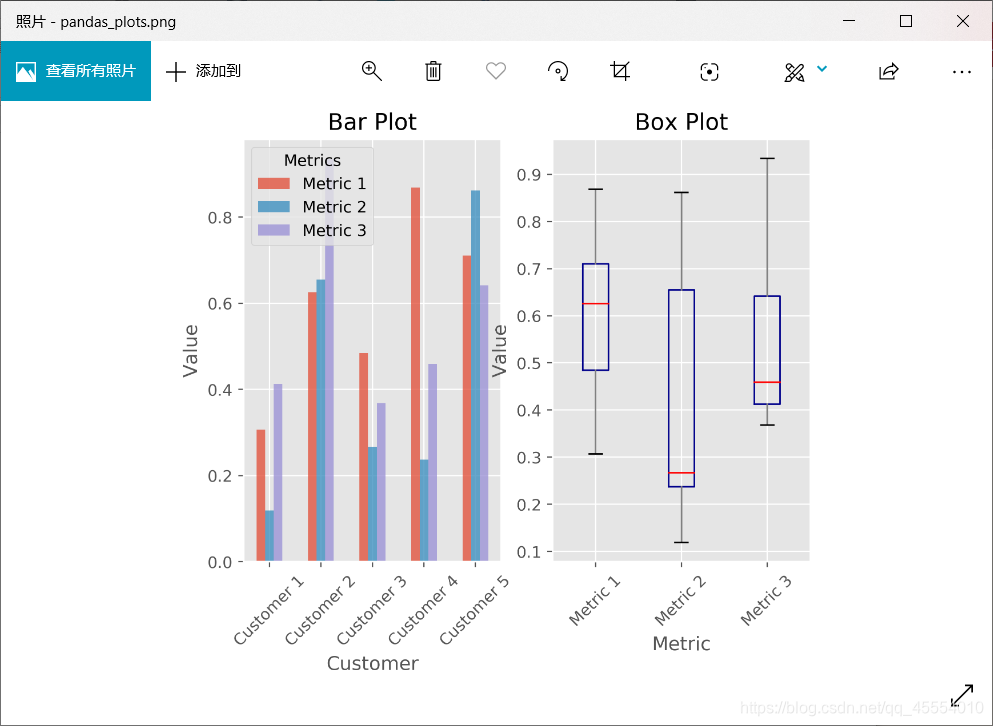
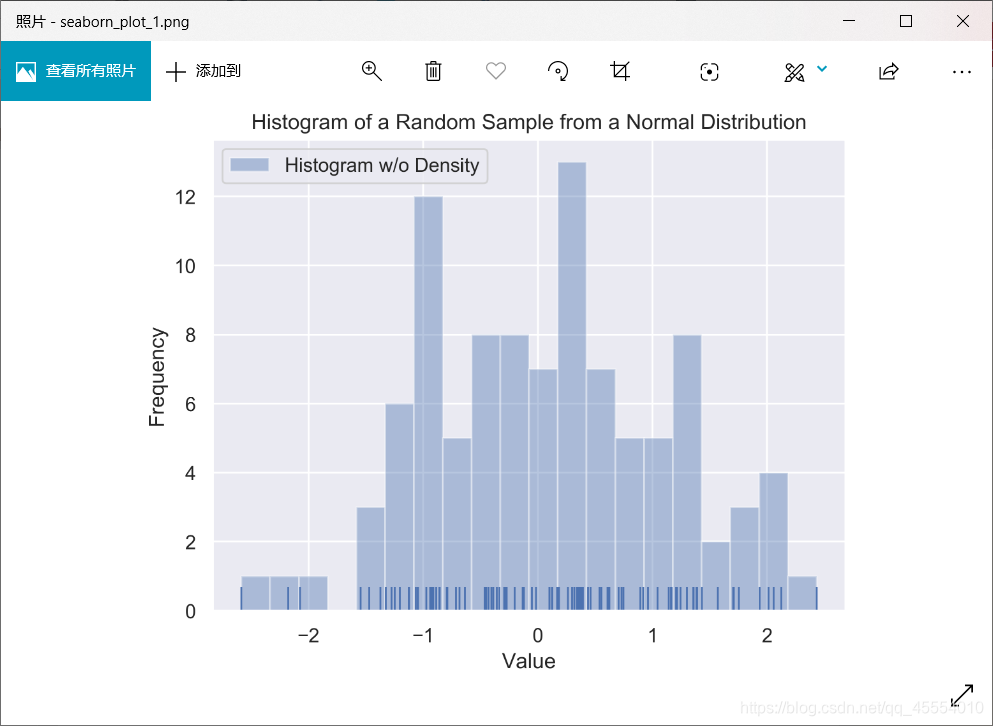 )
)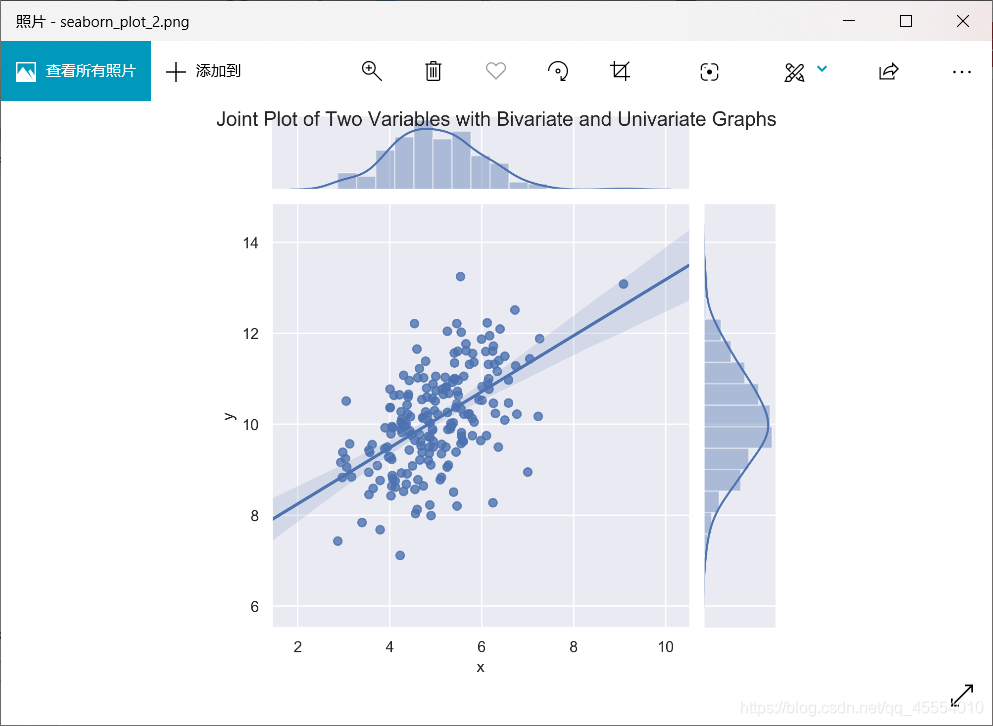 )
)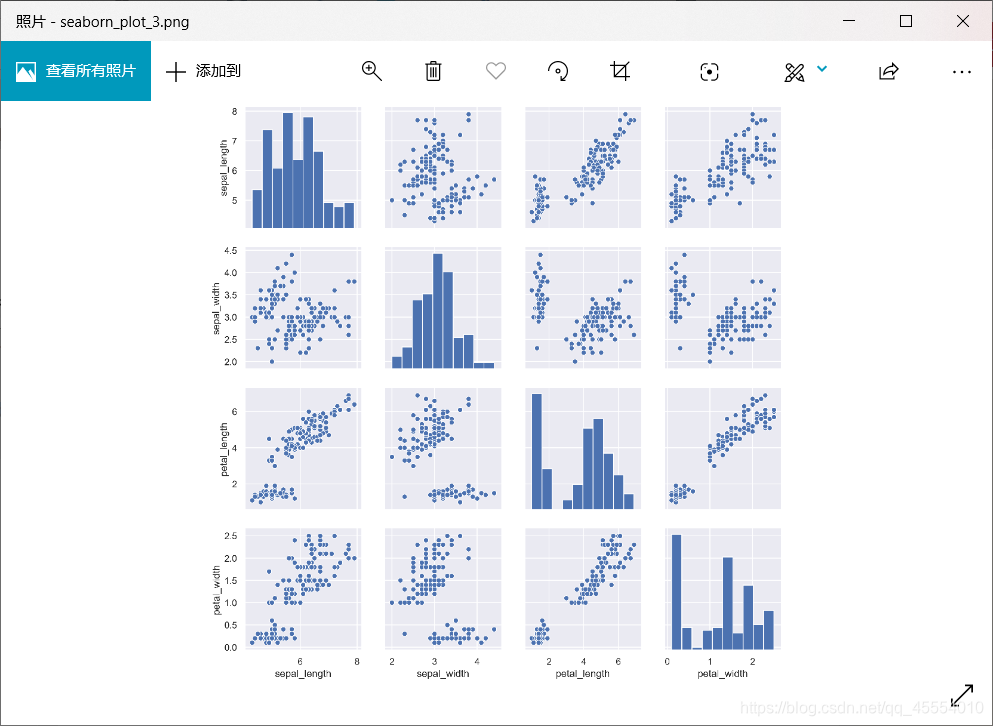 )
) )
) )
)